Serverless – AWS Lambda vs. Microsoft Azure Functions vs. Google Cloud Functions vs. IBM OpenWhisk Part 1
Posted by Žiko Petrović on 15 July 2020
Serverless, the new buzzword has been gaining a lot of attention from the pros and the rookies in the tech industry. But serverless is not just about the hype, it promises the possibility of ideal business implementations.
What is Serverless?
Serverless is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers. A serverless application runs in stateless compute containers that are event-triggered and fully managed by the cloud provider. Pricing is based on the number of executions rather than pre-purchased compute capacity.

Serverless is a concept/model where the developers build an application and they don’t care about the underlying infrastructure. It is similar to a PaaS but you only pay when the resources are used.
On FaaS, autoscaling is there by default. Behind the buzzword Serverless, there are still servers, but they are not the developer’s concern as the developer pays only for the function calls. All the installations, optimizations, and security updates of infrastructure are performed by the operator.
FaaS Advantages:
► Fewer developer logistics – server infrastructure management is handled by someone else
► More time focused on writing code/app logic – higher developer velocity
► Scalability – rather than scaling your entire application, you can scale your functions automatically and independently with usage
► Never pay for idle resources
FaaS is a relatively new concept that was first made available in 2014 and is now implemented in services such as AWS Lambda, Microsoft Azure Functions, Google Cloud Functions, and IBM OpenWhisk.

On a FaaS deployment, the costs depend on how much you use certain resources like RAM, CPU, network, or per number of requests. In terms of security, some aspects will be handled by the FaaS operator, but this doesn’t mean that your application will be bug-free of security issues. You still have to develop a secure application and follow best practices.
Serverless Providers Comparison
When it comes to serverless providers, there are many popular opinions based on various biases. Yet, while choosing serverless, there’s more to this than meets the eye. Considering how critical this is for long-term success, platforms should be evaluated based on their functionalities and service integrations.
AWS Lambda
Although statistics on serverless computing market share are elusive, AWS Lambda is probably the most popular serverless computing platform at the moment.
Lambda was the first serverless framework to become available from a major public cloud, and it helped to popularize serverless architectures. It is also the most popular provider used with the Serverless Framework.

{kind=link}
{kind=link}
{kind=link}
AWS Lambda was launched in November 2014 (preview release) but made available in 2015. With AWS Lambda, you can run your code for virtually any kind of application and backend service, without the need for provisioning or managing any servers. You get billed only for the compute time and are not charged when your code is not running. Lambda supports the execution of functions written in:
► Node.js
► Python
► Java
► C#
► Go
► Ruby
Each Lambda function runs in its own container. When a function is created, Lambda packages it into a new container and then executes that container on a multi-tenant cluster of machines managed by AWS. Before the functions start running, each function’s container allocates necessary RAM and CPU capacity. Customers get charged based on the allocated memory and the amount of run time the function took to complete. Customers don’t get much visibility into how the system operates, but they also don’t need to worry about updating the underlying machines, AWS takes care of this itself.
When building Serverless applications, to complete a Serverless stack you’ll need:
► a computing service
► a database service
► an HTTP gateway service
Lambda fills the primary role of the compute service on AWS. It also integrates many other AWS services and, together with API Gateway, DynamoDB and RDS forms the basis for Serverless solutions.
Popular Use Cases:
► Scalable APIs – When building APIs using AWS Lambda, one execution of a Lambda function can serve a single HTTP request. AWS Lambda automatically scales individual functions according to the demand for them so different parts of your API can scale differently according to current usage levels.
► Data Processing – Lambda functions are optimized for event-based data processing. It is easy to integrate AWS Lambda with data sources like Amazon DynamoDB and trigger a Lambda function for a specific data event.
► Task Automation – With its event-driven model and flexibility, AWS Lambda is a great fit for automating various business tasks that don’t require an entire server at all times.

{kind=link}
Azure Functions
The Microsoft cloud’s answer to AWS Lambda is Azure Cloud Functions, which became available in November of 2016. Azure Functions is the serverless compute offering by Microsoft that enables a user to run code on-demand.
The user doesn’t need to explicitly provision or manage infrastructure. Customers choose a language to host their code and then the appropriate platform is provisioned for running the code snippet. Scaling is taken care of automatically.

Image source: https://miro.medium.com/max/4200/0*WG-Yvr2yR3hpaZul.png
{kind=link}
There are two ways to purchase Azure Functions:
► Consumption plan – You are charged based on the runtime of your code in Azure Functions.
► App Service plan – If you already have App Service for other applications like web apps, you can run functions on the same plan with no additional cost.
Data processed by Azure Functions can persist into Azure data services such as Azure Storage, Azure SQL DB, and Document DB. Azure Functions supports the execution of functions written in:
► C#
► JavaScript
► F#
► Python
► TypeScript

{kind=link}
Azure Functions offers many powerful capabilities such as providing identity authentication easily to developers. Instead of having developers write code to take care of this, they can simply hook into the various identity providers in the Azure App Service to take care of authentication.
The core engine behind the Azure Functions service is the Azure Functions Runtime. The runtime is what makes the Azure Functions service work. When a request is received, the payload is loaded and the incoming data is mapped, and the function is invoked with parameter values. When the function execution is completed, an outgoing parameter is passed back to the Azure Function runtime.

{kind=link}
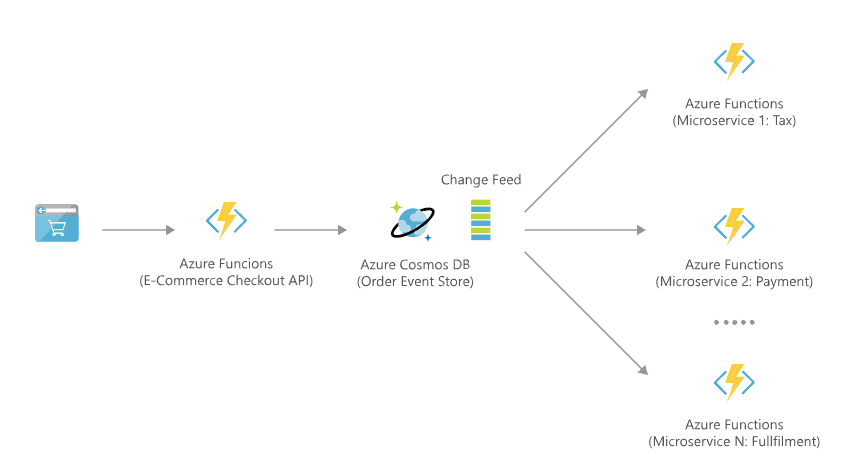
Popular Use Cases:
► Processing Data – Data can be processed by incoming batches. Multiple formats can be consumed by the functions and can run the conversion, cleaning, filtering, and other operations on the data.
► Integrating Systems – Functions provide a great way to integrate legacy system and code. Azure Functions can work as a proxy between the legacy applications and accept requests from the end-user or application and convert it into a format the legacy application understands.
► IoT Technologies – IoT is a huge use case in today’s modern environments. Functions allow efficient interaction with IoT devices and today’s applications.
► Simple APIs and Microservices – A powerful use case that allows breaking down large monolithic applications into smaller discrete function code triggered by events. Functions can be connected to other functions.
Conclusion – Part 1
In this part, we introduced serverless architecture and how it works. Also, we started talking about cloud providers and introduced AWS and Azure. In Part 2 we will continue our talk and introduce the other two (Google and IBM), and in the end, we will do a quick comparison of these four providers.

Žiko Petrović
Software Developer at PanonIT